Assignment 5 « Machine Learning»
Brief
- Due date: April 9, 2020 11:59PM
- Stencil:
cs1951a_install ml - Data:
/course/cs1951a/pub/ml/data - Handin:
cs1951a_handin ml - Files to submit:
README.txt,kmeans.py,song_clustering.py,img_compression.py,written_solutions.txt
Overview

Boomers have decided to explore machine learning because they are VERY tech-savvy and willing to learn. In this assignment you will help them accomplish various tasks and stay one step ahead of their mortal enemies, the bag ban and participation trophies. The goal of this assignment is to introduce basic machine learning concepts and provide a foundation for how to cluster data.
Assignment
In this assignment we will begin to explore the power data has in informing machine learning decisions. These boomers require an effective way to manipulate data attributes. Numpy is a python package that will help accomplish this. You will use the knowledge gained to help these boomers implement a K-means clustering algorithm. You will run this algorithm on two different datasets and implement sklearn's clustering algorithm on both data sets. Finally, you will make an elbow curve plot to discover the optimal number of centroids.
Part 1: K-means Algorithm
40 points
K-means clustering is an algorithm designed to sort data into groups based on similarity. To determine the groups, K-means repeatedly performs an update step, detailed by the following pseudocode:
For each data_point:
Determine closest centroid
For each centroid:
Determine centroid location as average of data_points which are closest to that centroid
To determine the closest centroid, you will be using a variation of Euclidean distance: distance = ∑i(ai - bi)^2 where ai, bi are the different features of data_point a and data_point b (hint: refer to the numpy way to calculate euclidean distance). To determine the centroids' new locations, you average together the data points for which that was the closest centroid. This means that a centroid is defined by its own feature set.
The real power of K-means comes from measuring distance with meaningful features of a dataset. For example, some meaningful features of a song might include its acousticness, danceability, and tempo. By applying K-means to a collection of songs, where the distance function between songs is based on these features, our resulting clusters will divide our songs into genres.
Part 1.1: K-means Class
In this assignment you will be implementing your own version of K-means. We have provided you with stencil code located inkmeans.py and specific instructions about the methods you will need to fill in. Your first step is to fill in the outlined methods which will later be used on two data sets to test your code.
Note: Please follow the input output specifications for each class member functions in the Kmeans class.
Part 1.2: Image Compression with K-Means
In this part img_compression.py takes in an image and breaks it up in RGB pixel values. It then uses these three values as features in your K-means algorithm to cluster by color similarity to compress the provided image. You do not need to change any code for this section, but run the file to see what clusters it returns.
For this problem, use the tiger.jpg image as the input to your program. To run the file, execute the following command:
$ python img_compression.py [-d PATH/TO/tiger.jpg]where
PATH/TO/tiger.jpg is the path to the image file. By default, without the -d flag, the data file path is ../data/ml/tiger.jpg. Successfully running the script will create files named centroids.txt and tiger.jpg in a new folder named output, which will contain the saved clusters and the compressed image.
Note: This part should take no longer than 30 minutes to run for 50 iters if your k-means is implemented correctly.
We have written a function img_distance which calculates an element-wise (pixel-by-pixel) difference. We won't be grading this difference, but to check if your k-means is implemented correctly, note that with K=16
and max_iters = 50, our distance is around 62. This is purely for your reference.
Part 2: Song Clustering
30 points
Part 2.1: Task Overview
Once you have filled out kmeans.py you can proceed to use your k-means class on clustering
songs by latent audio features. This data can be found in spotify.csv in the data directory
and consists of 600 top Spotify songs from 2010-2019.
We have included TODO comments in song_clustering.py to help with completing
this part of the assignment. You should only
have to edit functions in this file, and please note the input/output specifications of the functions,
as well as the expected output behavior (Part 2.6 below).
You will have to complete the following parts in the cluster_songs function, completing
additional functions as specified.
Part 2.2: Data Preprocessing
The original dataset consists of 13 features (Beats per Minute, Danceability, Acousticness, etc), but we will be using a subset of the features for the purposes of this assignment. We have written preprocessing code to extract three features from this dataset, specifically "acousticness", "speechiness", and "liveness". Your task is to use these three features to cluster the songs into clusters of similar songs.
Our preprocessing code removes outliers from the dataset. Please fill out the min_max_scale
function. Performing MinMax scaling prevents different scales of the data feature columns from
influencing distance calculations. Each column of the dataset should be standardized by the formula
found in the function's docstring.
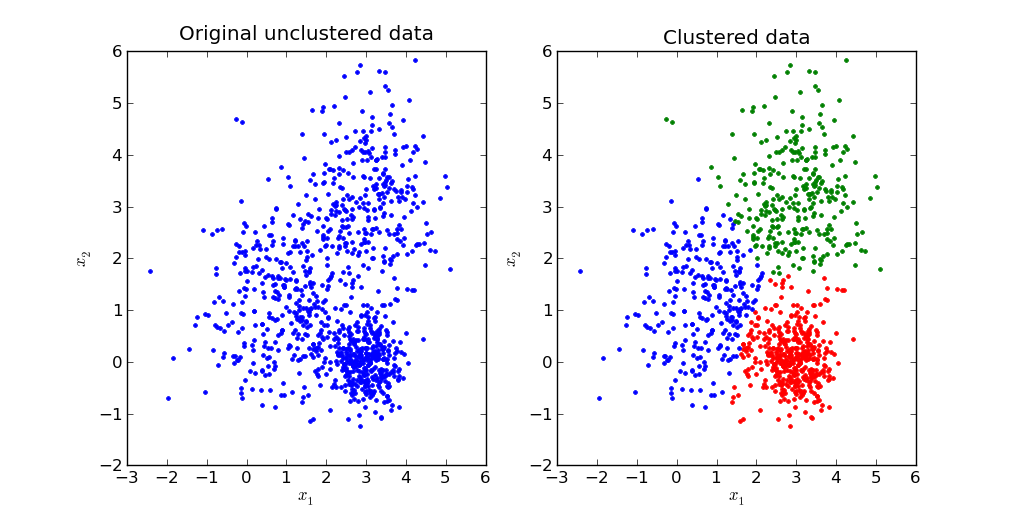
Part 2.3: Visualizing the Data
This dataset can be visualized in 3D, and we have written a function visualize_songs_clusters
to do so. You will use this same function to visualize the raw data as well as the cluster centroids
for both your custom kmean object and the library sklearn.cluster.KMeans object
(more details in Part 2.5).
By passing in optional centroids and centroid_indices arguments, you can visualize
each datapoint and which cluster it belongs to. Please note the optional is_lib_kmean argument
which should be set to True when visualizing results in Part 2.5.
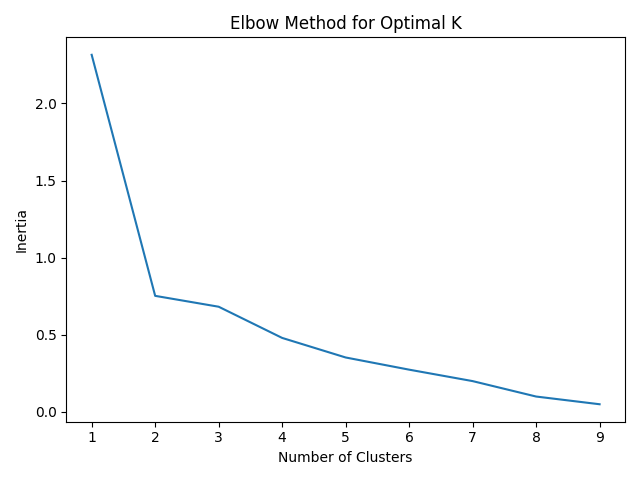
Part 2.4: Elbow Curve
Once you have written your k-means clustering algorithm, you might be wondering how many clusters should you use for a dataset. The number of clusters is called a hyperparameter of the machine learning algorithm and hyper parameter tuning is an important part of machine learning. One method to computing the number of clusters is plotting out the number of clusters and the inertia of the cluster assignments.
Inertia is defined as as the sum of the squared distances between each data point and the centroid of its assigned cluster.
As more clusters are added, inertia decreases. However, there are diminishing returns to this. The ideal number of clusters is a judgement call by looking at the “elbow point” of this graph where adding the next cluster does not significantly reduce inertia.
In song_clustering.py we have provided an elbow_point_plot() function that takes
in an np array of the number of clusters (x-axis) and an np array of inertia values (y-axis). The output
graph will be saved to the output directory as elbow_plot.png.
Analyze the graph and determine the ideal number of clusters. Below is an example of an
elbow point curve of a different dataset.
Part 2.5: scikit-learn
Programming machine learning algorithms is a good way to internalize concepts and get a better understanding
for how they work. However, in practice, machine learning libraries are often used to speed up data analysis.
For this part of the assignment, we will perform K-means clustering using scikit-learn, a popular machine learning library.
Click here to learn more about scikit-learn
and here
for the documentation on its KMeans class
Fill in the sk_learn_cluster function using sklearn.cluster.KMeans object.
The function takes in X - the dataset of Spotify data, and
K - the number of clusters and should output an np array where every index contains the
cluster of the corresponding vector as well as the coordinates of the cluster centers.
Hint: This can be done in just 3 lines of code!
You should also visualize your cluster results with the same visualize_songs_clusters used
previously, except this time with is_lib_kmean=True.
Part 2.6 Run Specifications
To run the file, execute the following command:
$ python song_clustering.py [-d PATH/TO/spotify.csv]By default, without the
-d flag, the data file path is ../data/ml/spotify.csv.
Calling visualize_songs_clusters will save the generated plot to the output folder.
You should call this function 3 times to generate plots of the raw data, clustered data
with your kmeans object, and clustered data with the sklearn.cluster.KMeans
object.
The cluster centers and centroid indices for each datapoint for both your model and the scikit-learn model
will be exported to a file named song_clusters.json. Note you must return these 4 items
from your cluster_songs function.
Successfully running the script will create the following files in your output directory based on
running solely song_clustering.py:
data_raw.pngdata_clusters.pngdata_clusters_sklearn.pngelbow_plot.pngsong_clusters.json
Working Locally
If you are working over ssh on a CS department computer, there are a few options for viewing the generated images fromimg_compression.py and song_clustering.py.
FUSE/SSHFS (Linux and Mac OSX)
SSHFS lets you mount a remote filesystem locally using SFTP. You'll be able to view, create, edit, and delete files on your local machine, and those changes will persist on a remote filesystem (in our case, the department machine filesystem). With FUSE, you can access all the files on your department machine in the file browser/terminal of your local computer.Download and Installations
Mac OSX
Linux
- If you don't already have
sshfs, runsudo apt-get install sshfs
Mount Filesystem
-
Open up the configuration file for your terminal (ex.
vim ~/.bash_profile) and add the following lines to the endalias myfuse='sshfs <your login>@ssh.cs.brown.edu:/gpfs/main/home/<your login> ~/browncs && cd ~/browncs' alias fixfuse='diskutil unmount force ~/browncs && myfuse'
Note: replace <your login> with your CS login i.e.alias myfuse='sshfs ayalava2@ssh.cs.brown.edu:/gpfs/main/home/ayalava2 ... -
Run
source ~/.bash_profilethen restart your terminal. -
Now, you should be ready to use FUSE/SSHFS. Run
myfusein a terminal window and you should be prompted to enter your login as if you were running ssh. After authenticating, you should be in the~/browncsdirectory on your local machine where you should find all your content from the home directory (~/) of a department machine. If you receive an error message with FUSE or when runningmyfuse, enterfixfuseto forcibly remount the filesystem.
Note: We recommend editing your files locally and running them on the department machines. When you are ready to run your files, you can SSH onto a department machine and run the code in the course virtual environment, like in previous assignments.
SCP
If you prefer working locally or remotely with a text editor like vim, you can use scp to transfer your files between your local machine and the department machines. Open up a terminal window and cd into the ml directory (either locally or in the home directory on a department machine.Note: Both of these scp commands assumes you are currently in the ml directory on your local machine and that you have not edited the file structure generated by the install script, that is,
~/course/cs1951a/<project>.
Sending Files
To send files, runscp -r ./* <your login>@ssh.cs.brown.edu:~/course/cs1951a/ml/
Receiving files
To receive files, runscp -r <your login>@ssh.cs.brown.edu:~/course/cs1951a/ml/. ./Ex.
scp -r ayalava2@ssh.cs.brown.edu:~/course/cs1951a/ml/. ./ You will be prompted to enter your password
(the same password for when you are trying to SSH into a department machine).
Windows users will have to install PuTTY and might have additional setup steps. Follow the directions here for Windows users.
Other Resources
Here are more resources for connecting to the department machines. Feel free to reach out on Piazza if you have issues.Part 3: Written Questions
30 points
Answer the following questions and save them to a file called written_solutions.txt.
- Explain how you structured your solution. What were the key parts of your K-means algorithm? Include any challenges you faced or shortcomings of your algorithm.
Explain your
closest_centroidsandcompute_centroidsimplementations. - What do the clusters mean in the context of image compression? How does changing the number of clusters impact the result of the song dataset and the image compression dataset?
- What is the difference between supervised and unsupervised learning? Give an example of an algorithm under each and an explanation for why they can be classified as a supervised or unsupervised algorithm.
- Read this article. Explain why the article argues that there's not one single concrete definition of "fairness." (2-4 sentences)
- Do you agree or disagree with this claim? Why or why not? (2-4 sentences).
Handing In
Your ~/course/cs1951a/ml folder must contain the following:
README.txtcontaining anything about the project that you want to tell the TAs. DO NOT INCLUDE YOUR CS LOGIN.kmeans.pysong_clustering.pyimg_compression.pywritten_solutions.txt
cs1951a_handin ml to hand in the files in that directory. Do not hand in the data files.
Credits
Made by your favorite TAs: Karlly, Huayu, and Arvind. Adapted from the previous TA staff for CS1951A. Spotify dataset sourced from Kaggle.